

Table of Contents
Concurrency issues can be tricky as they often arise when multiple requests hit your system at the same time, leading to unexpected behaviour and performance slowdowns. If you’ve ever dealt with race conditions or inconsistent data updates, you know how frustrating it can be. In this article, we break down the complexities of concurrent programming in Spring Boot and explore different strategies to handle them. Let’s dive in!
Problem Statement
Our challenge revolved around managing concurrent requests to our application, where each request was unique and had to be processed, unlike scenarios where idempotency ensures consistency, here, the distinct nature of each request necessitated special handling.
Our objective was to execute an upsert operation for incoming requests. If an entry exists, update it based on the logic; otherwise, create a new one.
Let’s take a simple example of a school keeping a record of marks scored by students.
Refer to the below schema of “Students”-
Problems with this upsert approach – Initially, the table is in an empty state.

We received three requests containing the student’s name, subject, and marks scored in that subject.
- Aman, English, 95
- Aman, Math, 96
- Aman, Physics, 98
Ideal scenario of data entry (If the requests were not concurrent)
- Marks scored in English get added to the Total Marks.


2. Marks scored in Math get added to the Total Marks (95+96=191)


3. Marks scored in physics get added to the Total Marks (191+98=289)

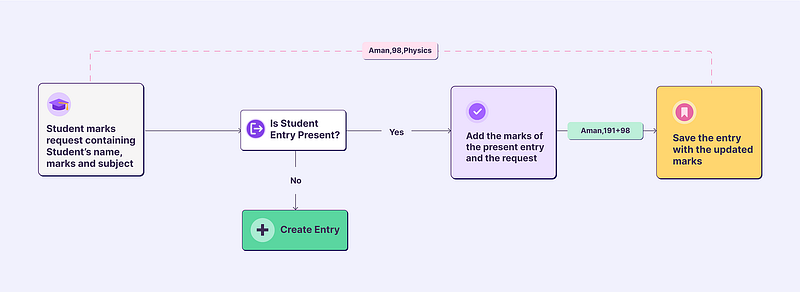
Considering the scenarios where we would have received concurrent requests:
- Consider the first 2 requests as concurrent
– Both requests for English and Math find no existing entry, leading to concurrent attempts to create the same student record.


– The 3rd request returns two entries instead of one, causing an. InvalidMethodArgumentException.
- If we had received the 2nd and 3rd requests at the same time.
– Below is the Table state after processing the 1st request-

– Both Math and Physics requests fetch the same table entry. Math updates the total marks to 191 (95+96), and Physics updates it to 193 (95+98). Since updates happen sequentially, if Math updates first, the final state will reflect Physics’ marks, as Physics doesn’t re-read the total marks.


After reading the above examples, you can get a clear picture of what problems one can face with concurrency.
Approaches
Here, we shall discuss some approaches we followed to address this issue. We’ll present code snippets for each approach and discuss their pros and cons.
- Unique constraint
- Redis locking
- Pessimistic locking + Unique key
- Optimistic locking + Unique key
UNIQUE Constraint
We can add a unique key constraint on the table such that no two rows can have the same value for fields marked as UNIQUE. When a request comes to insert a duplicate row, we get a data violation exception and handle it by doing a retry on getting this exception with backoff delay and max attempts configured.
This not only helps in data integrity but also improves read performance.
Limitation: This solution resolves the duplicate creation of rows in the table, but this will only work when we are doing an INSERT operation and not an UPDATE.
Note: You should be careful while adding keys or index on the table as it can lead to another impact; for example, in a write-heavy system, it will reduce the overall performance of the system
Here, we have used Retryable annotation of spring boot over this API. The delay can be similar to the time the entire functionality takes to complete. Also, set maxAttempts value to avoid infinite retry loops. Don’t forget to use @EnableRetry annotation on the application.
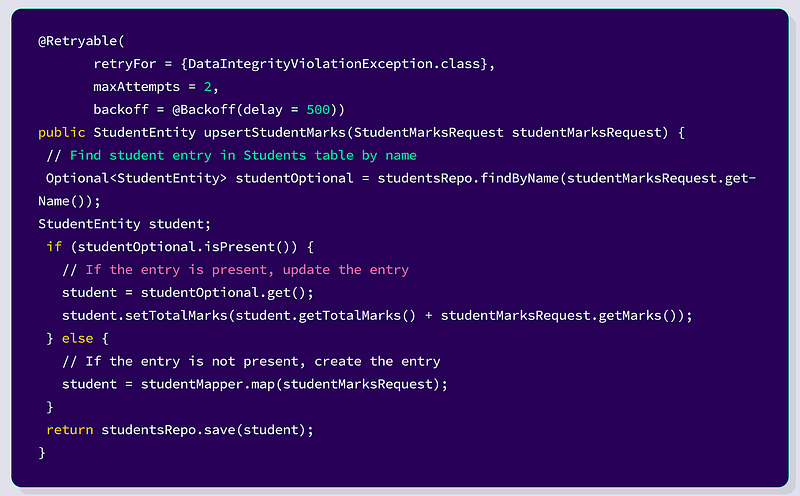
Let’s say we have received three concurrent requests for the same example.
- Marks scored in one of the subjects get added to total marks.

For the other two requests, DataIntegrityViolationException would be thrown as there is already one entry with the name Aman. This will lead to a retry for the other two requests.
- Now we are facing the same scenario where the last two requests come at the same time, so the request for other subjects will read the existing marks and update the entry to make a total of 191 (96+95), and similarly, the request for Physics will make a total of 194 (96+98). The final state of the table can contain 191 or 194.

Using this approach, we have resolved the issue where multiple entries were created but the problem of updating in case of concurrent requests still stands.
To handle concurrent insertions, adding a unique key to the table is not always possible. So, by leveraging the ACID nature of SQL, we can use a query like this.

Note: By adding a select query with insert, the time taken to insert will increase if proper indexing is not present on the table.
Redis Locking
Redis’s single-threaded nature ensures that only one command executes simultaneously, meaning concurrent requests are processed sequentially.
We create a Redis key from the input (e.g., ‘Aman’), ensuring concurrent requests use the same key.
The RLock interface in Java implements Lock and internally uses a semaphore. Reentrant locks (RLocks) prevent self-deadlocks by allowing the same thread to acquire the lock multiple times, ensuring smooth execution even in nested calls.

Let’s discuss the flow with our example by taking a case when we receive two concurrent requests.
- Any one of the two concurrent requests will acquire the lock first, as Redis is single-threaded. Let’s say that a request for English acquires the lock first.
– This creates a Redis entry with the key ‘Aman’ and value ‘{lock holder id, count = 1, ttl}’. The lock holder ID uniquely identifies the thread holding the lock.
– The second request tries to acquire the same lock but finds the ‘Aman’ key in Redis, so its thread is blocked. The lock can be released in two ways. When the first thread releases lock or if the lock’s TTL (1 second in this case) expires, allow the second request to proceed.

- When the first thread releases the lock by calling the unlock() function, the Redis key ‘Aman’ is deleted once the count reaches zero. It also publishes an unlock message to the Redis pub/sub channel, notifying other waiting threads that the lock has been released. This allows the second thread to acquire the lock and proceed through the critical section, just like the first thread.

Let’s look at the problems with the above approach.
- Blocking: If another thread or process already holds a lock, the current thread will block, potentially leading to competition for the resource.
- Redis Downtime: Failure to acquire a lock due to Redis being down can result in code blocking unnecessarily.
Non-Blocking Redis Lock — To avoid the above problems we can use an approach to tryAcquireLock.

Code for Releasing RLock

Note: To handle the non-blocking nature of tryLock, we will need a retry logic to ensure that all the requests are executed.
Pessimistic Locking
In this approach, when a transaction accesses a resource (such as a database row), it acquires a lock on that resource. This lock prevents other transactions from accessing or modifying the resource until it is released. This ensures that only one transaction can modify the resource at a time, thus preventing conflicts and maintaining data integrity.


Why are we using @Transactional?
We are performing both read (findByName) and write (save) operations to the database in upsertStudentMarks method. Transactional blocks ensure that if any operation fails, the entire transaction is rolled back. A pessimistic lock is tightly coupled with a transaction and is held for the duration of the transaction. Without the transaction, the lock would immediately be released after the query is completed.
Let’s discuss this in detail with our example of 3 concurrent requests.
- All three requests check if the entry with the name is present and don’t find any entry. Remember that pessimistic locking holds a lock on a resource, but the resource (row) is not present yet, so pessimistic locking does not come into the picture now. Assuming that the request for math is processed first, its entry gets created, and for the other two requests, we get SQL error as we use unique key constraints. In such a case, we use a similar retry mechanism as used in our above approach for a unique key constraint.


- With pessimistic lock, the findByName would change to SELECT * from Students where name = ? for UPDATE. This locks the rows as if they are already being updated. Other transactions trying to access these rows are placed in a queue, managed internally by the database, to ensure they are executed in order once the lock is released.


- When the transaction for English is committed, the lock is released, and the SELECT .. for UPDATE query for physics, which was blocked, can now execute. The final table state would look like this.

Optimistic Locking
Unlike pessimistic locking, which assumes conflicts will occur and proactively acquires locks, optimistic locking assumes conflicts are rare and handled only when necessary.
Versioning or Timestamps: Each database record has a version number or timestamp that tracks its last update.
Read Phase: When a transaction reads a record, it also retrieves its current version number or timestamp.
Validation Phase: Before committing changes, the transaction checks that the version or timestamp hasn’t changed since it was first read. If it matches, the transaction proceeds; if not, it aborts.
Commit Phase:
- If no changes are detected (version/timestamp matches), the transaction commits.
- If changes are detected (version/timestamp mismatch), the transaction aborts, indicating stale data, and retries the operation.
Minimal Locking Overhead: Optimistic locking reduces the need for locks during the read and update phases, only detecting conflicts at commit time.

Here, we are retrying on ObjectOptimisticLockingFailureException, which occurs when optimistic locking fails. It indicates that another transaction has updated or deleted the same database record the current transaction tries to modify, resulting in a version conflict. Also note that we have increased the maxAttempts because, unlike pessimistic locking, which locks the resource and blocks the other transactions, optimistic locking always tries to update and encounters exceptions whenever it fails. This leads to retry on every concurrent request.

@OptimisticLocking(type = OptimisticLockType.DIRTY) tells Hibernate to use “dirty” optimistic locking, meaning the version is checked only when fields in the entity are actually modified. For this approach, Hibernate generates UPDATE statements that include only the modified fields in the WHERE clause, enabled by the @DynamicUpdate annotation.
Note: We can manually implement optimistic locking with a native query like: UPDATE Students SET totalMarks=? WHERE id=? AND totalMarks=? Instead of relying on annotations.
Coming to the explanation with our example of receiving three concurrent requests
- Similar to pessimistic locking, due to the unique key on the name, we encounter DataIntegrityViolationException for the two requests that are later served by the database.
- The two requests for Physics and English are retried using the @Retryableannotation. Both follow the same flow until they reach the update step. The English request attempts to update the total marks to 191 (95+96), while the Physics request tries to update the marks to 194 (98+96).
Assume the English update succeeds first, changing the table’s state. The update query for Physics will be UPDATE Students SET totalMarks=194 WHERE id=1 AND totalMarks=96. Since the total marks have already changed to 191, this query fails, leading to an ObjectOptimisticLockingFailureException.


- The request for Physics will be retried, and the marks will be updated without issue. Note that our flow is executed 3 times for three concurrent requests, and it would increase with the increasing number of concurrent requests.
Conclusion
The following table provides a comparative analysis of Redis Lock, Optimistic Locking, and Pessimistic Locking, highlighting their key differences and best-use scenarios.
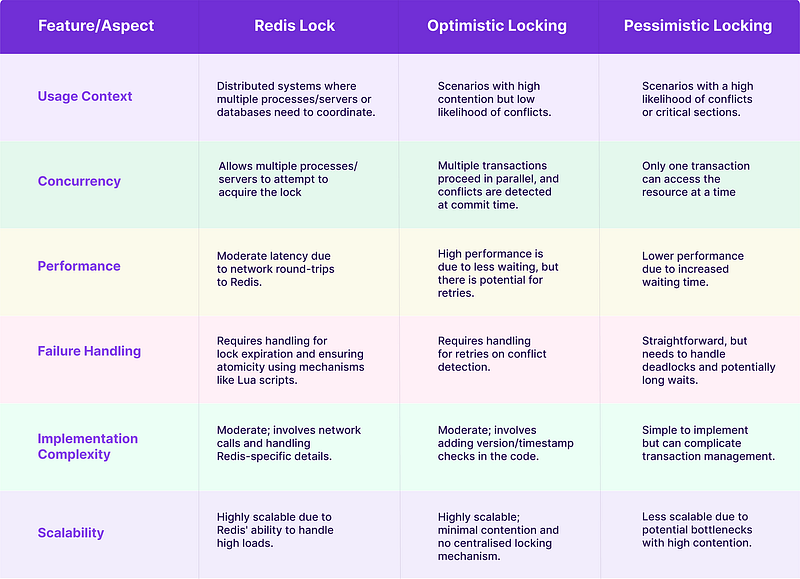
While Redis locking provides a lightweight and efficient mechanism for handling concurrent requests, database-level strategies like pessimistic and optimistic locking ensure data integrity under different use cases. The choice of the best approach depends on system requirements, workload characteristics, and performance considerations. By carefully selecting and implementing these strategies, developers can build scalable and robust applications that handle concurrency efficiently.


